Численные методы
Пришла пора начать новый раздел и рассмотреть более прикладное применение программирования: численное решение различных математических задач.
В этой главе нам предстоит научиться находить нули и экстремумы функций с заданной точностью, приближённо вычислять площадь под графиком функции, а также длину кривой.
Численные методы
Существует множество математических объектов, задач, конструкций, которые позволяют проводить анализ теоретических объектов и получать математически правильный ответ. В математике, например, существует известное вам число \(\pi\) – оно является трансцендентным, то есть представимым исключительно в виде бесконечной непериодической десятичной дроби. С этим числом можно проводить расчеты, писать его в ответ. Другим примером трансцендентного числа является число \(e\), которое, как правило, определяется как предел последовательности \(e := \lim_{n \to \infty} (1 + \frac{1}{n})^n\) или как сумма бесконечного ряда: \(e:= \sum_{n = 0}^{\infty} \frac{1}{n!}\).
Это все корректно определенные математические понятия, но в прикладных задачах реализовать и использовать бесконечность невозможно. Понятно, что для практических задач достаточно знать число \(\pi\) с конечной и весьма небольшой точностью. Нам не обязательно знать, что корнем уравнения является \(\frac{1 + 2 \sqrt 5}{3}\), достаточно понимать, что это \(\frac{1 + 2 \sqrt 5}{3} \approx 1.824045318333193\)
Численные методы – это совокупность приемов, которые позволяют реализовывать математические определения за конечное количество операций с числами. Часто это включает учет машинной точности, приближенное решение задач, алгоритмические приемы в решении уравнений, например. В этой главе мы познакомимся с некоторыми базовыми алгоритмами.
Нули функции методом половинного деления
Как известно из уроков математики, нули функции \(f(x)\) – корни уравнения \(f(x) = 0\). Разобьем область определения функции на отрезки, в каждом из которых находится ровно один нуль функции (он также не совпадает с границами выделенных отрезков). Математически:
\[ D(f) = [a_1; a_2] \cup [a_2; a_3] \cup \dots \\ \ \\ \forall i \ \exists ! \ x \in [a_i; a_{i + 1}] : f(x) = 0 \]
Постановка задачи: построим алгоритм, который позволит искать с точностью \(\varepsilon\) нуль функции \(f\) на отрезке \([a; b]\), если известно, что в этом отрезке содержится ровно один нуль функции (\(x_0 : f(x_0) = 0\)). То есть будем искать такое \(x_*\), что \(|x_* - x_0| < \varepsilon\).
\(m := \frac{a + b}{2}\) – середина отрезка
если \(f(a) < 0\), то есть если функция меняет знак с \(-\) на \(+\), см. график справа
\(f(m) \ge 0 \Rightarrow x_0 \in [a; m]\), то есть стягиваем правую границу отрезка: \(b = m\)
\(f(m) < 0 \Rightarrow x_0 \in [m; b]\), то есть стягиваем левую границу отрезка: \(a = m\)
если \(f(a) > 0\), то есть если функция меняет знак с \(+\) на \(-\)
\(f(m) \ge 0 \Rightarrow x_0 \in [m; b]\), то есть стягиваем левую границу отрезка: \(a = m\)
\(f(m) < 0 \Rightarrow x_0 \in [a; m]\), то есть стягиваем правую границу отрезка: \(b = m\)
повторяем пункты выше, пока \(|b - a| > \varepsilon\)
затем \(x_* = \frac{a' + b'}{2}\) – середина итогового отрезка
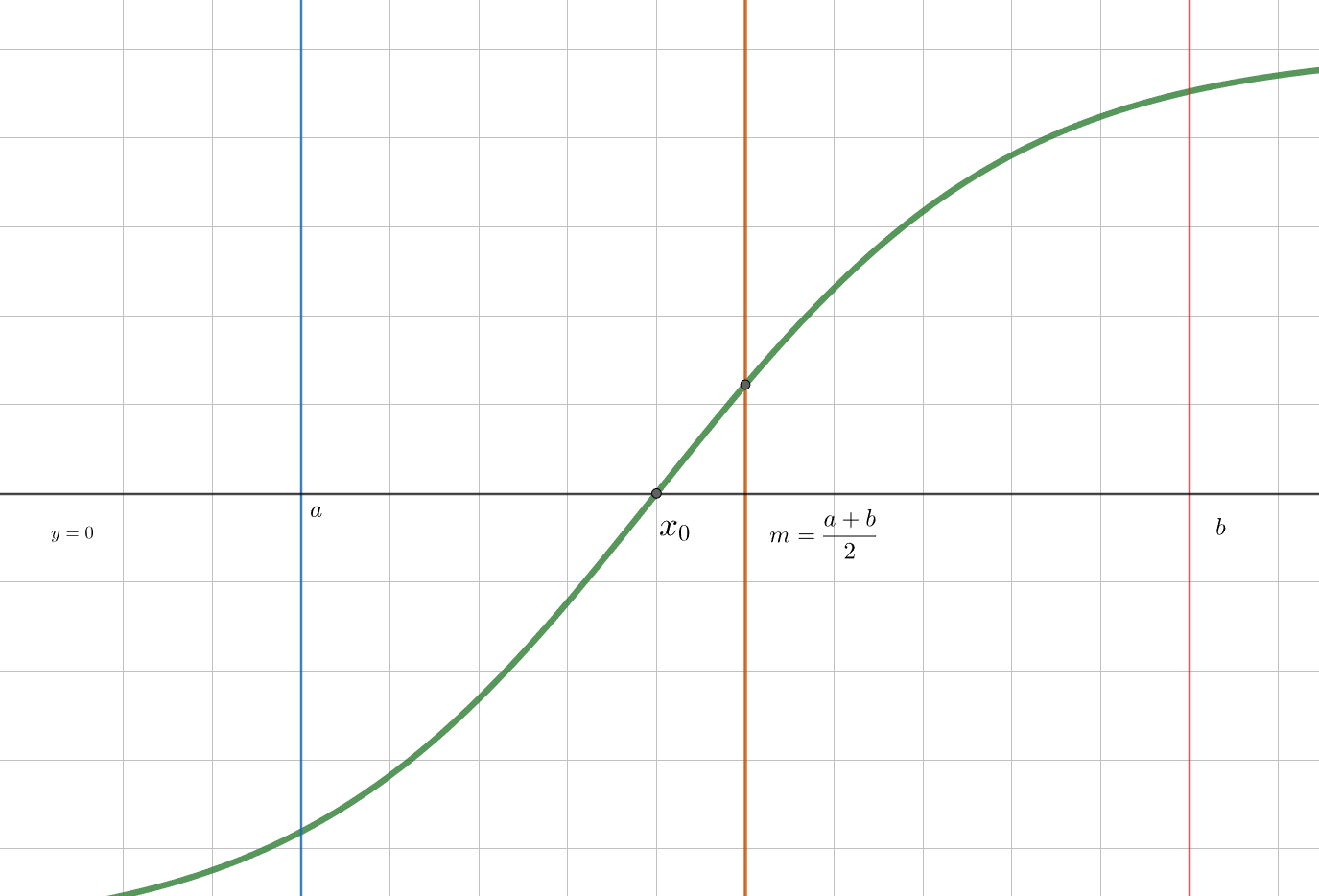
Заметим, что точка \(m\) по построению делит отрезок \([a; b]\) пополам, значит, каждая итерация уменьшает рассматриваемую область в 2 раза. Рассчитаем сложность алгоритма.
\[ \begin{gathered} L_k = b_k - a_k \text{- размер отрезка поиска после k-той итерации} \\ \ \\ L_k = \frac{1}{2} L_{k - 1} = \left( \frac{1}{2} \right)^k L_0 \\ \ \\ \ \frac{\varepsilon}{2} \le L_n \le \varepsilon \\ \ \\ \frac{\varepsilon}{2} \le \left( \frac{1}{2} \right)^k L_0 \le \varepsilon \\ \ \\ \frac{\varepsilon}{2 L_0} \le \left( \frac{1}{2} \right)^n \le \frac{\varepsilon}{L_0} \\ \ \\ \ \log_{(\frac{1}{2})} \frac{\varepsilon}{2 L_0} \ge n \ge \log_{(\frac{1}{2})} \frac{\varepsilon}{L_0} \\ \ \\ \ \log_{2} \frac{2 L_0}{\varepsilon} \ge n \ge \log_{2} \frac{L_0}{\varepsilon} \\ \ \\ \ \log_{2} \frac{L_0}{\varepsilon} \le n \le 1 + \log_{2} \frac{L_0}{\varepsilon} \Rightarrow n = {\cal{O}} \left( \log \frac{L_0}{\varepsilon} \right) = {\cal{O}} \left( \log \frac{b - a}{\varepsilon} \right) \end{gathered} \]
Таким образом, алгоритм имеет логарифмическую сложность и гарантирует, что для любой точности \(\varepsilon\) найдется приближенный корень.
Также метод половинного деления называют методом дихотомии или методом бисекции.
Шаблон кода
#include <iostream>
#include <string>
#include <iomanip>
#include <cmath>
#include "fparser.hh"
#ifndef YA_CONTEST
#include "fparser.cc"
#endif
double findRoot(FunctionParser& function,
double left, double right, double eps) {
while (/* условие: отрезок достаточно велик */) {
double mid = /* ? */;
if (/* f меняет знак на [left, mid] */) {
/* обновляем границу */
} else {
/* обновляем границу */
}
}
return /* приближённое значение нуля */;
}
int main() {
std::string function_line;
while (std::getline(std::cin, function_line)) {
FunctionParser function;
function.AddConstant("pi", 3.1415926535897932);
function.AddConstant("e", 2.7182818284590452);
function.Parse(function_line, "x");
double a, b;
int eps_pow;
std::cin >> a >> b >> eps_pow;
double eps = /* ? */;
std::cout << std::fixed << std::setprecision(6)
<< findRoot(function, a, b, eps) << '\n';
std::cin.ignore();
}
}Подсказка: знак функции на отрезке можно проверить по знаку произведения \(f(a) \cdot f(m)\).
Экстремумы функции методом половинного деления
Унимодальная функция имеет ровно 1 экстремум (минимум или максимум). Мы будем рассматривать унимодальные на отрезке функции – те, которые на данном отрезке имеют ровно один экстремум.
Экстремум функции – это такая точка, в некоторой окрестности которой все значения функции больше (или меньше) значения в этой точке. То есть если брать точки, близкие к точке максимума, то значения функции в них будут меньше. Более формально:
\[ x_0 - \operatorname{max} \stackrel{\text{def}}{\Leftrightarrow} \exists \varepsilon > 0: \forall x \in [x_0 - \varepsilon; x_0 + \varepsilon] : f(x) < f(x_0) \]
Аналогично можно записать определение для минимума функции.
Теперь применим уже знакомый нам алгоритм для поиска экстремума. Рассмотрим на примере максимума.
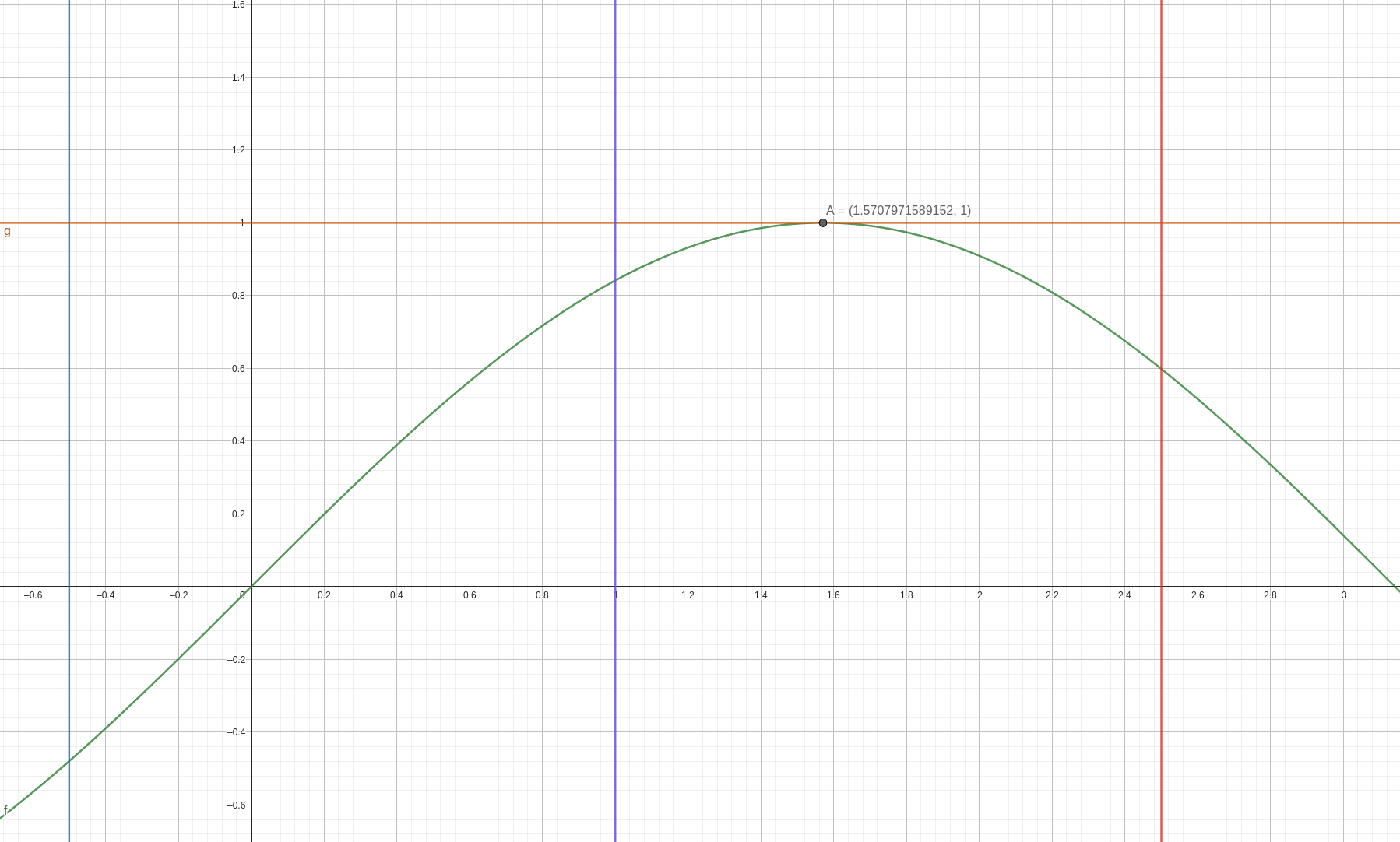 Здесь показана унимодальная на отрезке функция, границы отрезка и выбранное значение \(m\)
Здесь показана унимодальная на отрезке функция, границы отрезка и выбранное значение \(m\)
Заметим, что в случае максимума функция возрастает до точки максимума и убывает после нее.
\(m := \frac{a + b}{2}\) – середина отрезка
\(x_1 := m - \delta\), \(\ \ \ x_2 := m + \delta\), \(\delta \approx 10^{-5}\) – выбираем 2 точки, очень близкие к середине
если \(f(x_1) < f(x_2)\), то есть если функция возрастает в окрестности середины, то середина находится слева от точки максимума
- \(x_{max} \in [x_1; b]\), то есть стягиваем левую границу отрезка: \(a = x_1\)
если \(f(x_1) > f(x_2)\), то есть если функция убывает в окрестности середины, то середина находится справа от точки максимума
- \(x_{max} \in [a; x_2]\), то есть стягиваем правую границу отрезка: \(b = x_2\)
повторяем пункты выше, пока \(|b - a| > \varepsilon\)
затем \(x_{max} = \frac{a' + b'}{2}\) – середина итогового отрезка
По сути все, что поменялось – метрика, по которой мы выбираем левую или правую половину отрезка. Поскольку \(\delta\) выбирается малой, на каждой итерации длина рассматриваемого отрезка сокращается в 2 раза, поэтому асимптотика сохраняется.
Площадь под графиком
Определённый интеграл функции \(f(x)\) на отрезке \([a; b]\) геометрически представляет собой площадь под графиком функции. Точное аналитическое вычисление интеграла возможно далеко не всегда, поэтому используют численные методы.
Идея: разбить отрезок \([a; b]\) на \(n\) равных частей и приблизить функцию на каждом малом отрезке более простой функцией, площадь под которой легко посчитать.
Разобьём отрезок \([a; b]\) на \(n\) равных частей точками \(x_0 = a, x_1, x_2, \dots, x_n = b\) с шагом \(h = \frac{b - a}{n}\).
Способы приближения функции на отрезке
На каждом малом отрезке \([x_i; x_{i+1}]\) зададим функцию \(f_{approx}(x)\), которая приближает \(f(x)\). Рассмотрим несколько способов:
Левый прямоугольник: \(f_{approx}(x) := f(x_i)\) — константа, равная значению функции в левом конце отрезка
Средний прямоугольник: \(f_{approx}(x) := f\left(\frac{x_i + x_{i+1}}{2}\right)\) — константа, равная значению функции в середине отрезка
Трапеция: \(f_{approx}(x) := f(x_i) + \frac{f(x_{i+1}) - f(x_i)}{h} \cdot (x - x_i)\) — прямая, соединяющая точки графика функции на границах отрезка. Это линейная функция с угловым коэффициентом \(\operatorname{tg} \alpha = \frac{f(x_{i+1}) - f(x_i)}{x_{i+1} - x_i}\)
Правый прямоугольник: \(f_{approx}(x) := f(x_{i+1})\) — константа, равная значению функции в правом конце отрезка
Метод прямоугольников
В методах 1, 2, 4 функция приближается константой на каждом отрезке. Площадь каждого прямоугольника: \(S_i = f_{approx} \cdot h\). Формулы суммарной площади:
Левые прямоугольники: \(\displaystyle S = h \cdot \sum_{i=0}^{n-1} f(x_i)\)
Правые прямоугольники: \(\displaystyle S = h \cdot \sum_{i=1}^{n} f(x_i)\)
Средние прямоугольники: \(\displaystyle S = h \cdot \sum_{i=0}^{n-1} f\!\left(\frac{x_i + x_{i+1}}{2}\right)\)
Метод трапеций
В методе 3 функция приближается прямой, и площадь фигуры под ней — трапеция:
\[ S_i = \frac{f(x_i) + f(x_{i+1})}{2} \cdot h \]
Суммарная площадь:
\[ S = \sum_{i=0}^{n-1} S_i = h \cdot \left( \frac{f(x_0) + f(x_n)}{2} + \sum_{i=1}^{n-1} f(x_i) \right) \]
Иллюстрация: https://www.geogebra.org/calculator/cxwmudtz
Все четыре метода имеют сложность \({\cal{O}}(n)\). Чем больше \(n\), тем точнее приближение.
Длина кривой
Длина кривой \(y = f(x)\) на отрезке \([a; b]\) — ещё одна величина, которую можно вычислить приближённо. Идея та же: разбиваем отрезок на \(n\) частей и заменяем кривую ломаной.
На каждом отрезке \([x_i; x_{i+1}]\) заменяем кривую хордой — отрезком прямой, соединяющим точки \((x_i, f(x_i))\) и \((x_{i+1}, f(x_{i+1}))\). По сути это то же линейное приближение (метод 3), но вместо площади под прямой мы вычисляем длину самой прямой. Длина хорды — расстояние между двумя точками:
\[ \ell_i = \sqrt{(x_{i+1} - x_i)^2 + (f(x_{i+1}) - f(x_i))^2} = \sqrt{h^2 + (f(x_{i+1}) - f(x_i))^2} \]
Приближённая длина кривой:
\[ L \approx \sum_{i=0}^{n-1} \ell_i = \sum_{i=0}^{n-1} \sqrt{h^2 + (f(x_{i+1}) - f(x_i))^2} \]
Сложность алгоритма: \({\cal{O}}(n)\).